
Intellify's Guide To Handle Incremental Data Processing
Today we are living in the world of information where in data is the new oil. We are surrounded by interconnected devices and voluminous data is generated constantly. This in-comprehensible data needs to be structurally stored, deeply analysed and logically processed to draw constructive observations and conclusions. In such a scenario it becomes very important that BI (Business Intelligence) implementation companies use best practices to store and process the data. Data Processing is the core function and faster the processing power, more is the business.
1. Introduction
As we all know our transactional systems data is growing every day and will continue to grow at an exponential rate with every passing instance.
This data needs to be analysed with near real time speed to understand the latest trends.
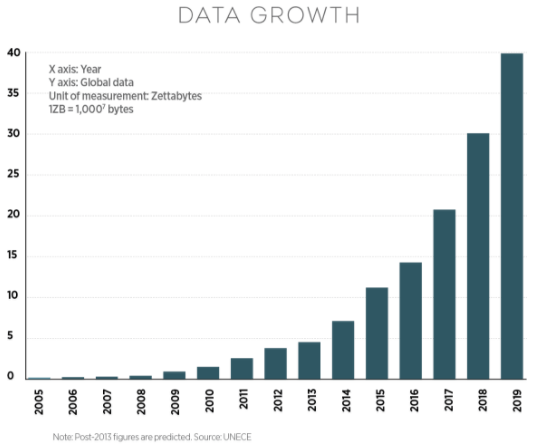
BI implementation companies have to handle such kind of data every time and produce intelligent visualisations. It is overwhelming to handle such a data in short time and produce reports which impact the decision making.
t is a well-established fact that SQL Server Analysis Services (SSAS) are the most stable when it comes to handling growing data so that it is accessible and available at all times with the decision makers.
2. What is Incremental Cube Processing?
OLAP (Online Analytical Processing) cube is a method of storing data in a multidimensional form, generally used for reporting purposes. OLAP cubes are often pre-summarized across dimensions to improve query performance.
Cube processing is nothing but having pre-summarized data across dimensions. To do this it takes, Time, CPU usage and Memory. These 3 factors dramatically get affected if data volume is very large and so one should process the parts of cubes which are modified. This is called Incremental Data processing.
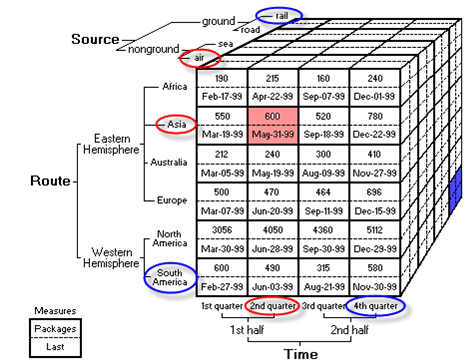
3. What are different scenarios that one can run into while doing incremental cube processing
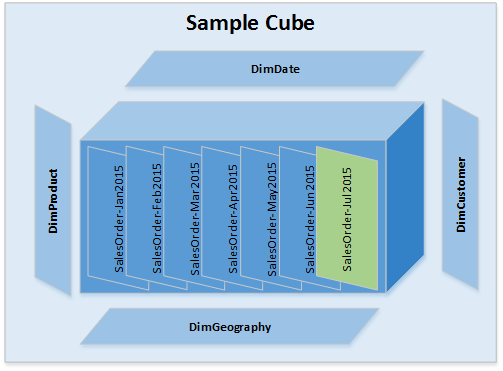
1. Delta Data Scenario 1
Happy Path Scenario (There is a Delta data for Facts (only Current Partition) but Dimension Data is same) – Refer Image – 1 – All Green boxes should be processed.
-
Fact Tables – Identified Delta data is for current Partition only. E.g. Partitions are based on Month Year key for Order date. So all Orders placed during Jan2015 will have aggregation placed in “SalesOrder-Jan2015” Partition.
-
Dimension Tables – There are no new Dimension Members or there are no updates to existing dimension members.
-
Processing Steps – Process cube for current month say SalesOrder-Jul2015.
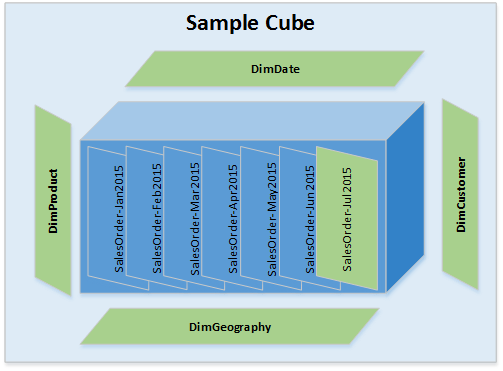
2. Dimension Data has Delta (There is Delta Data for Facts (only Current Partition) & there are some Dimensions with Delta Data ) – Refer Image – 2 – all green boxes will should be processed
-
Fact Tables – Identified Delta data is for current Partition only. So in the above example Delta data for Facts table is only for Jul2015 month.
-
Dimension Tables – There are New Dimension Members or there are Updates to existing dimension members.
-
Processing Steps – Process Dimensions. 2. Process cube for current month say SalesOrder-Jul2015. There is no need to process other dimensions.
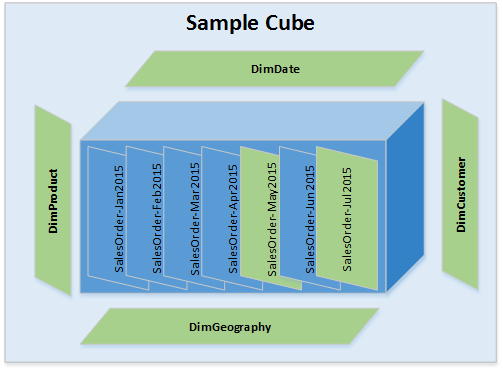
3. Previous Partitions data is modified along with Delta for Facts and Dimensions (There is Delta Data for Facts (Current & Previous Partitions) & there are some Dimensions with Delta Data ) – Refer Image – 3 – all green boxes will should be processed
-
Fact Tables – Identified Delta data is for current & Previous Partitions. So in the above example Delta data for Facts table is for May2015 & Jul2015 months.
-
Dimension Tables – There are New Dimension Members or there are Updates to existing dimension members.
-
Processing Steps – Process Dimensions. 2. Process cube for current month say SalesOrder-Jul2015 & SalesOrder-May2015.
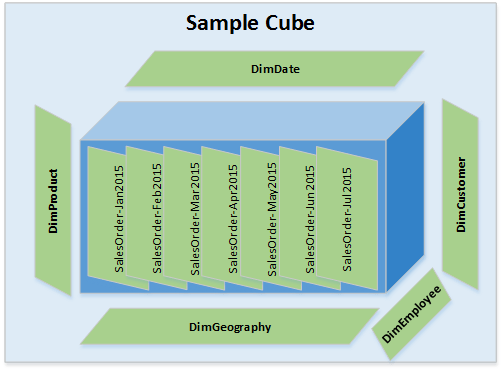
4. New Dimension is added to cube with Delta for Facts (There is Delta Data for Facts (Current Partition) & there are some Dimensions with Delta Data) – Refer Image – 4 – all green boxes will should be processed
-
Fact Tables – Identified Delta data is for current & Previous Partitions. So in the above example Delta data for Facts table is for May2015 & Jul2015 months.
-
Dimension Tables – There are New Dimension Members or there are Updates to existing dimension members. Also there is New Dimension added to the cube.
-
Processing Steps – Process Dimensions. 2. Process entire cube for all partitions.
-
-
-
This should help users in refreshing SSAS Cubes quickly by processing smaller sets of data as shown in the above scenario.
For all the BI implementation companies, data processing is the core function. With enhanced processing power, visualisations can be rendered with micro details and thus help the client with deeper insights into the business.