
What are Recommendation Engines?
What are Recommendation Engines?
We humans are more inclined to buy products or services which are recommended by other people we trust like friends, relatives, colleagues or general trend of what other people are buying. These recommendations are based on their perspective on what we may like and what is trending in the market currently. The issue with this approach is these recommendations are not personalized to our needs and features we may be interested in. This is where modern recommendation engines helps us to personalize our search.
Modern Recommendation Engines are very useful as they help users identify or search items one might be interested in which otherwise are difficult to find using traditional search algorithms or typical ratings based indexes.
Recommendation Engines are used to recommend an item based on user ratings or user preferences based on various attributes of that item. The engine recommends items to a user considering the user preferences or item features a user might be interested in based on the historical data available of that user and items.
Some of the examples are like Financial Portals recommending products based on previous searches, Credit Card companies recommending better products based on user’s spending patterns and repayment history.
How Recommendation Engines work?
There are various techniques which are used to recommend a product or service.
Some are based on predefined indexes which are then used to recommend a product or service to the user. E.g. Insurance Products marked to be promoted by Insurance Companies and Banks, other Sponsored Items etc.
Some are based on simple aggregated ratings either explicit or implicit like customer star ratings, survey based ratings, based on frequency of purchase like top items, more frequent items, most popular items etc.
More advanced engines uses more detailed approach to recommend based on individual purchase history. These recommendations are targeted for that specific user and are more specific and more effective. These types of engines make clear distinction between explicit and implicit data collection.
Challenges & Constraints to consider while selecting the approach –
The recommendation models described above have some drawbacks and they do not address some of the issues alone. Some of them are
First Rate – Products which are not rated will not get recommended
Popularity bias – The model recommends highly rated or popular Products
Cold Start Problem – When new item/product gets introduced in the market, it does not have any user ratings or a purchase history. Models considering these parameters might not recommend these products.
Sparsity of Data – User’s may not buy all products and rate them. This creates a large pool or items which are not rated or has very less no. of ratings considering user base and available products or services creating a sparse matrix.
Scalability – There are millions of users and products available and a large amount of computation power is required to calculate and build the recommendation models.
Feature Selection – It is very difficult to identify appropriate and relevant features in complex searches like image processing, music and movie recommendations.
Model Evaluation – Model evaluation is important in assessing the effectiveness of recommendation algorithms.
Types of Recommendation Engines
There are multiple ways to build or develop a recommendation engine. This decision is taken based on multiple aspects of the recommendation model and the intent of the model. Typically what features / aspects / buyer’s / domain which are impacting the recommendations, helps you decide which model type will give you more appropriate recommendation. Below diagram depicts some of the techniques –
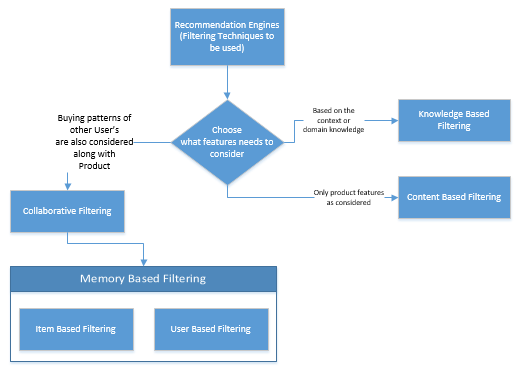
Models based on Content or features
These models use historical data along with various features of an item to recommend additional items with similar features. Some of the examples are –
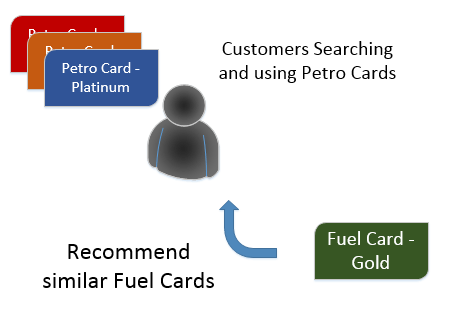
- Recommend Platinum Card as the user rated Gold Card
- Recommend an Insurance Plan based on features searched
- Recommend a Credit Card based on ratings a user has given to similar Cards
For Content Based Models – we need to calculate Similarity Score using different techniques available. There are 5-6 different techniques namely – The Euclidean, The Manhattan, The Minkowski, The Pearson and The Jaccard and The Cosine Similarity scores. Each one having its’ own advantages / disadvantages.
Similarity Measure is the measure of how much alike two data objects are. Similarity measure in a data mining context is a distance with dimensions representing features of objects. Similarity is proportional to distance. More about Similarity Score in our separate blog.
Advantages of Content based filtering-
- They can recommend new items even if the database does not contain user preferences.
- If user preferences change, it has the capacity to adjust its recommendations in a short span of time.
- This is also used where different users do not share the same items, but only identical items according to their intrinsic features.
- Users can get recommendations without sharing their profile, and this ensures privacy.
Disadvantages of Content based filtering-
- There is dependency on the availability of descriptive data – Content based filtering techniques are dependent on items’ metadata and organised user profile before recommendation can be made to users.
- Content overspecialisation – is another problem. Users are restricted to get recommendations similar to items they already have in their profiles.
Models using Collaborative approach
In this approach the model is developed considering purchase history of the user for a given item along with purchase history of similar item by other users. The collaborative approach uses either “User to User” similarity approach or “Item to Item” similarity approach.
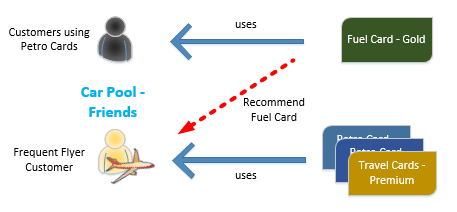
“Item-to-Item” Similarity approach: the recommendation is based on historical data collected for similar items for which the recommendation is made. For e.g. an item is recommended to a user similar to the item user is searching or buying for. This approach promotes users to try different products they might not have tried earlier or not aware of their availability. E.g. New flavour of ice cream. A different sized or shaped soda can.
Advantages with Collaborative Filtering –
- They perform in domains where there is not much content associated with items and where contents are difficult to analyse.
- They has the ability recommend items that are relevant to the user even without the content being in the user’s profile.
Challenges with Collaborative Filtering
- Cold-start problem – When recommender does not have adequate information about a user or an item in order to make relevant predictions. In short – new user or item do not have or rated any item.
- Data sparsity problem – When only a few of the total number of items available in a database are rated by users. This leads to a sparse user-item matrix, inability to locate successful neighbours, resulting to the generation of weak recommendations. Data sparsity leads to coverage problems
- Scalability – A recommendation technique that is efficient when the dataset is small may not be effective when the volume of data increases. There are Dimensionality reduction techniques, such as Singular Value Decomposition (SVD) method, which has the ability to produce reliable and efficient recommendations.
- Synonymy – it is the tendency to have different names to same item. Most recommender engines find it difficult to make distinction between such closely related items. Automatic Term Expansion, the Thesaurus, Singular Value Decomposition (SVD), Latent Semantic Indexing can be used to address this issue.