
Open Source Conversational AI Rasa
Existing NLP BOT Solutions like Alexa, Google DialogFlow, etc. is using services from Amazon or Google, etc. which requires data to be passed out of the premises. Enterprises including financial institutions are very finicky about security and doesn’t really like going outside their premises for any services. They insist on having On-Prem solutions as far as possible without exposing any of the customer data to any third-party applications or solutions. Do we have any options for On-Prem NLP-Bot solutions? Fortunately, we do have inexpensive and very professional standard solutions available.
The moment we talk of some such solutions – we have so many queries like, does it support Voice and Text both? Does it support multiple languages? What kind of Hardware we need to support such solution? What different Channels (Phone, Web text, Web Voice etc) it supports? Etc.
There is industry standard solution (framework) available and it does answer all above questions in affirmative – Rasa. It helps in building your on-prem solutions and framework is very innovative in its approach.
What is Rasa?
Rasa an open source framework which supports NLP Bot concept and it gives complete flexibility to customize things. Below Diagram is very high-level diagram of Rasa. I will be explaining each component in little more detail to get good understanding of complete Rasa.
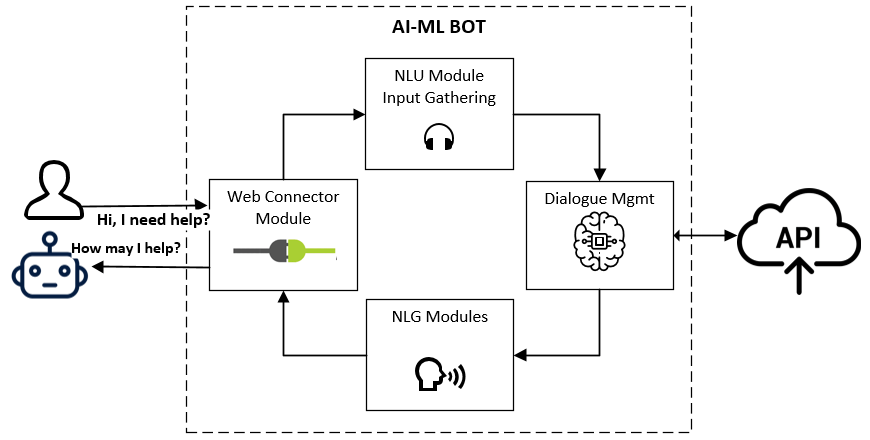 Mainly there are 4 components viz Connector module, NLU Module, Dialogue Management module and NLG Module.
Mainly there are 4 components viz Connector module, NLU Module, Dialogue Management module and NLG Module.
Connector Module –
This module helps in connecting NLP Bot Framework with different channels like Web, Google Agent, and Social Media like Facebook, Slack etc. There are some out of the box connectors available and can be used to quickly integrate.
NLU Component –
NLU component consist of multiple sub-components and they play very vital role in understanding what is said. Following are some of the components as part of NLU –
- Word Vector Sources
- Featurizers
- Intent Classifiers
- Tokenizers
- Entity Extractors
Word Vector Sources – this is where Language model is loaded and should be specified at the beginning of configuration. There are mainly two – Mitie and Spacy. Mitie is used for small data set of utterances compared to Spacy. Mitie might be deprecated in near future and it performs well on small datasets. In case of couple of hundred examples – training model gets very slow and time consuming.
Featurizers – There are different Featurizers and those are used for different purposes like Features for Intent Classification, Entity Extraction etc. E.g. MitieFeaturizer, SpacyFeaturizers creates features for Intent Classification. RegexFeaturizer is used for Entity Extraction.
Intent Classifiers – These classifiers (classifies Intent from user query) are used for Intent Identification and may or may not take inputs from Featurizers. Some of the Intent Classifiers also output Intent Ranking. KeywordIntentClassifier, MitieIntentClassifier, skLearnIntentClassifier EmbeddingIntentClassifier are some of the examples. Some of these Classifiers require Tokenizer and Featurizer as part of complete settings.
Tokenizers – These tokenizers help in cerating tokens used by Mitie entity extractor. WhitespaceTokenizer, JiebaTokenizer (specially used for Chinese language), MitieTokenizer, SpacyTokenizer are some of the Tokenizers available.
Entity Extractor – This component identifies and lists all the Entities (parameters from the user query). Some of the Entity extractors are – MitieEntityExtractor, SpacyEntityExtractor, EntitySynonymMapper, CRFEntityExtractor, and DucklingExtractor.
Steps involved in NLU when any new message processing –
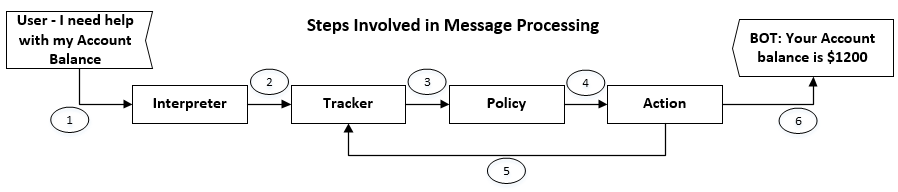
On receiving new message – it’s passed onto Interpreter, Message is converted into Original Text, Intent and Entities (Slots). This is part of NLU.
The Tracker has responsibility of keeping track Conversation State. Policy receives the current state of Tracker. Policy decides what action to be taken next and chosen action is logged into Tracker and response is sent to User.
Once Pipeline components are decided, Intents and Entities are defined along with Training data – below diagram is typical shows Spacy pipeline working.

Dialog Management Component –
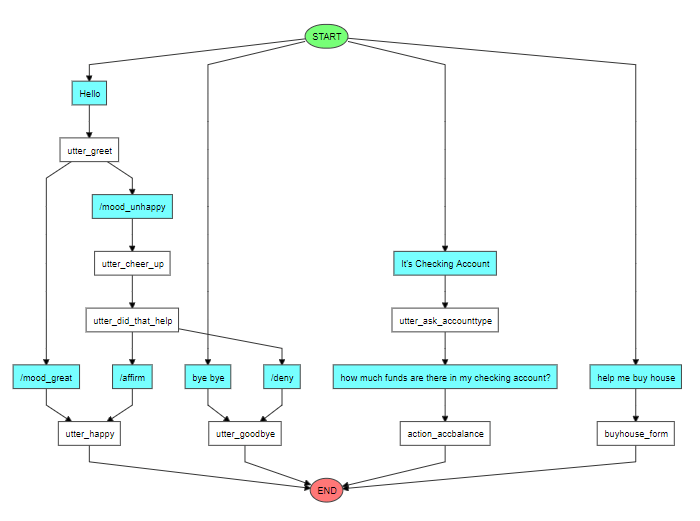
In this component Rasa decides what next steps (action to be invoked) to be taken based on the Dialog Management module it’s trained. Rasa internally creates a flow chart based on Dialog Management it’s trained with. Below is one example for same. As part of action – Rasa can connect Web APIs for bringing more data from web server.
Sample Diagram for Conversation flow is given below –
NLG Module –
This module is responsible for Generating User response by taking inputs from Action and Passing it on to User.
Are there any other alternatives to Rasa?
Conversational chats bots can be built using Natural Language Tool kit – but then more components need to be built for saving the conversation context and other things. Rasa has made things much easier by providing framework where you can alter things with little changes in Configuration. Even Custom Components like Sentiment analysis can be added as part of NLU Pipeline.
We at Intellify, have POCs ready for Consumer Banking Sector. Our expertise lies in Designing Conversation flow, Integration with your current web portal and multi-lingual implementation. Please contact us for more details.
Credits – Rasa